
1. 概述
1.1. 业务领域
规则引擎是一种软件系统,通过预定义的规则实现自动化决策。它能够接收输入数据,并根据设定的逻辑规则进行处理,从而得出结论或采取行动。规则引擎的核心特点是灵活性和可扩展性,可以根据业务需求快速调整和添加新规则。
这种引擎衍生出了许多成熟的复杂系统,如风控引擎、反爬引擎、流程管理和智能决策等。这些系统在频繁变更的业务环境中,可以显著降低业务变更率,最多可达70%。在当今的中台技术和各类业务领域,规则引擎发挥着极其重要的作用。
下图是规则引擎在小红书风控系统中所扮演的角色(架构图涉密,已做混淆处理):

1.2. 实际应用
以风控引擎为例举个具体例子,在登陆场景中,有许多黑灰产企图通过撞库攻击、暴力破解、会话劫持等方式掌控用户账号并非法获利,风控从业人员可能配置如下规则来确保用户为可信用户:
-
异常登录检测:
- 规则:如果用户在短时间内尝试多次登录失败,则标记为可疑。
- 表达式:
登录失败次数 > 3 AND 时间间隔 < 5分钟 → 标记为可疑
-
地理位置监控:
- 规则:如果用户在不同国家或地区的IP地址下短时间内登录,则提示风险。
- 表达式:
当前登录IP与上次登录IP 地理位置不同 AND 时间间隔 < 1小时 → 提示风险
-
设备指纹分析:
- 规则:如果用户使用的设备与之前记录的设备不符,则进行额外验证。
- 表达式:
当前设备ID ≠ 上次登录设备ID → 触发额外验证
-
时间模式识别:
- 规则:如果用户在异常时间段(如深夜)登录,则进行风控检查。
- 表达式:
登录时间 NOT IN [8:00-22:00] → 进行风控检查
-
行为异常分析:
- 规则:如果用户在登录后进行异常高频的交易或操作,则触发风险警报。
- 表达式:
操作频率 > 10次/分钟 AND 登录后 → 触发风险警报
通过这些规则,风控引擎可以实时监测和评估登录行为,及时识别潜在风险,保护用户账户安全。
我们可以将规则简化为 A + B ≠ C。为了判断该表达式是否成立,首先需要获取 A、B 和 C 的具体值(我们称之为因子)。假设我们通过请求参数直接获取了 A 的值,那么接下来需要利用因子之间的依赖关系来挖掘 B 和 C 的值,这个过程称为特征补全。最终,根据表达式的结果,风控引擎将决定是放行还是拦截登录请求。
2. 架构设计
为了理顺规则引擎的主线逻辑,我们面临三个关键技术难点:特征补全、规则判断和仿真验证。
此外,为了确保规则引擎的有效运行,还需实现极致的性能优化和容灾备份等技术措施。实际应用中,还应设计因子血缘关系、因子上探下钻、灰度测试和回放演练等辅助功能,以增强系统的灵活性和可靠性。
在性能优化方面,作为实时决策的规则引擎面临巨大的技术挑战。例如,在小红书,风控引擎需要承受百万QPS的高并发,同时保证TP999在80毫秒以内。因此,我们在规则引擎的架构设计中将看到许多熟悉的解决方案(赞美前人的智慧)。
2.1 特征补全
在之前的讨论中,我们提到因子这个概念,简单来说,它们就是表达式中的关键字。因子的值可以通过直接获取或间接计算。对于间接计算的因子,我们需要理清它们之间的依赖关系,才能找到合适的计算渠道。这里我们将不同的因子类型大致分为四类:
-
常量因子:这些因子的值几乎不变,比如用户注册时的手机号、设备硬件信息等,它们通常存放在KV数据库里以供直接取用。
-
名单因子:名单因子一般也是直接从KV数据库中读取,它们通常涉及不同层面的黑白名单信息,一般由专门的服务维护,其技术细节并不简单。
-
累计因子:在风控领域,了解历史行为对于判断流量风险至关重要。累计因子就是从某个时间窗口内累积的指标值,比如累计登录次数等。
-
外部因子:这类因子通过远程调用外部系统来获取,复杂性最高。因为微服务间的调用链难以预测,可能会导致系统超时,如何避免超时、限流且及时降级容错也正是规则引擎的技术难点之一。
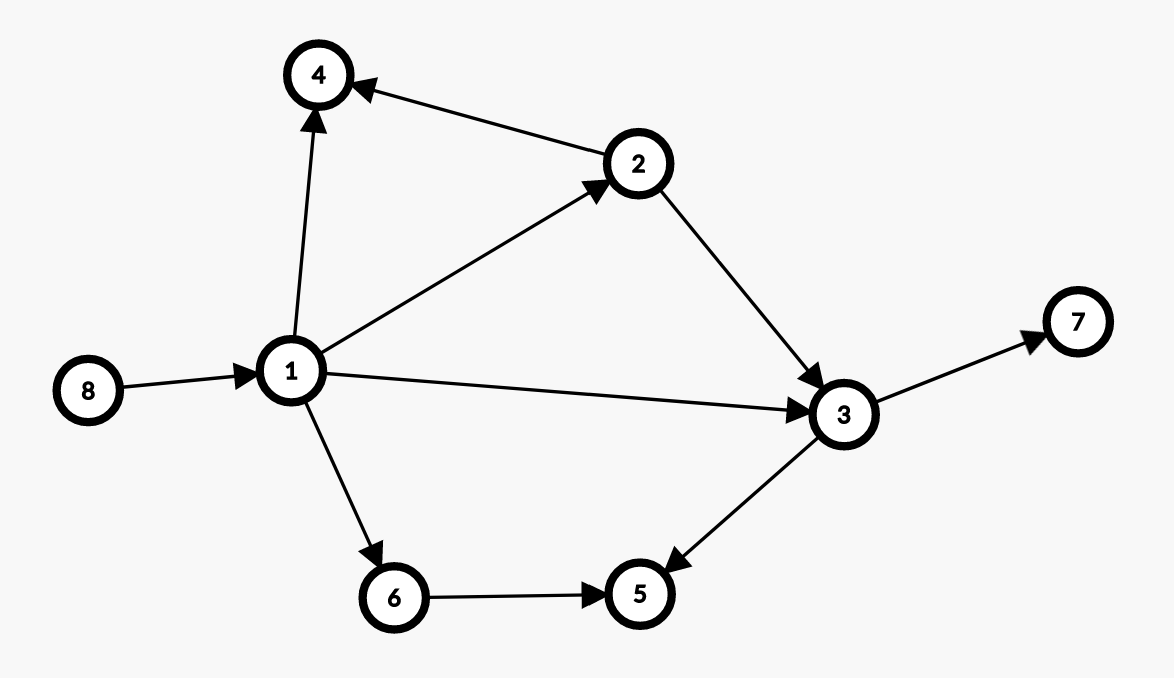
为了维护大量因子之间的关系,业内普遍采用有向无环图(DAG)的结构,通过拓扑排序计算线性关系,并依次进行计算。例如,在下图中,计算顺序为:8 -> 1 -> 2 -> 3 -> 6 -> 4 -> 5 -> 7。在这个顺序中,节点 2、3、6 和 4、5、7 各自内部的顺序是相对无序的,可以自由调换。
因此,在实际应用中,通常会使用二维容器来存储排序结果。在每个“桶”内以及“桶”之间进行顺序上的微调,其目的是将来自相同数据库或数据源的因子尽可能聚集在一起,以便进行批量操作和并发计算。这种方法不仅提高了处理效率,还能减少对数据库的频繁访问,从而优化整体性能。
2.3 规则判断
规则判断是在获得因子值的基础上,对特定场景下的大量表达式进行验证的过程。在这一过程中,场景之间通常存在父子关系,例如在登录场景中可细分为高峰和平峰。表达式又可分为聚合类型和嵌套类型。在有限的响应时间内,处理大量表达式的判断是个不小的挑战。
在小红书的实现中,我们采用了谷歌开源的Aviator表达式引擎(用Java编写),并在此基础上扩展了更复杂的算子和聚合函数。这一扩展使得我们能够支持更灵活的表达式评估,从而满足多样化的业务需求。
具体实现方面,我们结合了批计算和流计算的技术,尽可能加快规则判断的速度。批计算允许我们在处理大规模数据时,优化计算资源的使用;而流计算则能实时处理动态数据,确保及时响应。在处理过程中,我们将表达式分类存储,采用多线程处理技术,以提高整体计算效率。
2.4 仿真验证
仿真验证是指将规则的执行流程透明地反馈给用户,并支持对结果进行评估。这一过程包括对压测和流量回放的支持。
以流量回放为例,每当引擎进行重大更新时,我们会将过去记录的流量在新的集群上重新运行,以观察其效果。这种做法有助于评估引擎在新环境中的性能提升,确保更新不会导致意外问题。
在实现上,我们会:
-
数据收集:定期收集历史流量数据,并确保数据的完整性和准确性。
-
环境搭建:在新的集群上搭建与生产环境相似的测试环境,以便真实地模拟流量。
-
流量重放:使用流量重放工具,将历史流量数据发送到新集群,观察引擎的响应和处理效果。
-
结果分析:对比更新前后的结果,分析性能指标(如响应时间、成功率等),评估能力提升。
通过仿真验证,我们可以有效识别潜在问题,确保引擎在重大更新后的稳定性与性能。
3. 性能优化
3.1 同步策略
为了实现卓越的性能,规则引擎通常通过提高CPU利用率来弥补IO操作的延迟。以小红书的规则引擎为例,系统启动时会将所有磁盘数据加载到本地内存中,并在之后每5分钟进行一次同步。
@Override
public synchronized void reload() {
loadDataSource();
loadFactors();
buildFactorDependencies();
validateFactorDependencies();
loadRules();
buildRuleFactorAssociations();
loadRuleGroups();
loadScenarios();
loadStrategies();
loadScenarioRoutes();
loadPlaybackTasksAndRules();
loadStrategyGreyVersions();
buildScenarioTreePath();
}
从上述代码可以看出,每次同步是分块进行的,数据库中的数据和关系在内存中通过字典记录和维护,DAG的构建也在这个过程中完成。分块后,我们可以使用 ForkJoinPool(Java内部的线程池)进行高效的并发计算。
然而,这种方式也存在隐患。例如,一次数据同步可能需要1分钟,随着数据量的增加,这个时间可能超过定时任务的周期,导致无效的同步。
为了优化这一过程,字节跳动的内容风控平台采用了Nacos配置下发的优化策略,结合“推拉”机制。具体来说,不仅定时主动推送数据,还利用长连接监控数据变化。同时,通过分块策略来减少长连接的数量,从而降低连接池的压力,这一设计灵感来源于分段锁的思想。
这种“推拉结合”的方式,使得数据同步更加灵活高效,确保了系统在处理大量数据时的稳定性和响应速度。
3.3. DAG剪枝
在规则引擎中,DAG(有向无环图)用于表示因子之间的依赖关系和计算顺序。然而,随着规则和因子的增加,DAG的复杂度可能导致性能下降,特别是在计算和评估大量表达式时。因此,进行DAG剪枝是一种有效的优化策略。
什么是DAG剪枝?
DAG剪枝是指通过移除不必要的节点和边,以简化图的结构,从而提高计算效率的过程。具体来说,它可以帮助消除冗余依赖,降低计算复杂度。
剪枝的常见策略
-
消除无效节点:识别并移除不再参与计算的因子或规则。例如,某些因子可能在特定场景下不被使用,剪枝可以减少对这些因子的计算。
-
合并相似节点:当多个因子或规则具有相同的计算逻辑时,可以考虑合并这些节点,减少重复计算的需要。
-
动态剪枝:根据实时数据和业务需求,动态调整DAG的结构。例如,当某个因子在一段时间内不再被触发时,可以暂时移除它的相关依赖,减少计算负担。
-
静态分析:在规则引擎启动时,进行静态分析,识别并删除不必要的依赖关系和计算路径。这可以有效降低后续计算的复杂性。
剪枝的优点
- 提升性能:减少不必要的计算,降低资源消耗,提高响应速度。
- 降低复杂度:简化DAG结构,使得规则引擎的维护和扩展更加高效。
- 提高可读性:清晰的依赖关系和计算路径,便于开发和调试。
通过合理实施DAG剪枝,规则引擎能够在高负载情况下保持高效运行,同时提高系统的可维护性和扩展性。但博主没见过具体实施方案,没法深入介绍。
3.4 响应式计算
响应式计算是一种优化DAG中因子值计算的策略,通过对因子进行排序以明确执行路径,使得所有因子可以进行异步计算。这种方法旨在提高CPU利用率,从而加速整个计算过程。
响应式计算的工作原理
-
因子排序:首先,对因子进行拓扑排序,以明确它们之间的依赖关系和执行顺序。这确保在计算某个因子之前,其所有上游因子已经完成计算。
-
异步计算:一旦因子被排序,所有因子就可以进入异步计算状态。每个因子的计算可以在独立的线程中执行,并且如果因子未收到上游因子的回调则会阻塞。一旦其依赖的上游因子完成,当前因子会立即开始执行剩余的计算逻辑。
-
回调机制:使用回调函数处理因子的计算结果。当某个因子的所有上游因子完成后,触发当前因子的计算,这样可以避免等待所有因子的计算完成,从而提高整体计算的并行性。
通过这种响应式计算的方式,因子可以并行处理,不必在等待上游因子的计算完成后再进行执行,从而优化了整体性能。这种机制能够有效提高CPU的利用率,并降低计算延迟。
性能挑战
尽管响应式计算在性能上显著提升,但也可能引入一些挑战,尤其是毛刺现象(spike):
- 计算波动:各个因子的计算时间可能不均匀,某些因子在计算时长上可能出现剧烈波动,导致整体系统性能表现不稳定。
- 资源竞争:在高并发计算时,多个因子争夺CPU和内存资源,可能导致资源过度消耗,从而影响系统的响应时间。
为了实现响应式计算,可以采用以下代码示例:
private List<Future<String>> submitFactorTasks(List<FactorCaller> callers, Task task) {
return callers.stream()
.map(caller -> factorExecutorService.submit(() -> caller.call(task)))
.collect(Collectors.toList());
}
在这个实现中,我们利用Java的ExecutorService来提交因子计算任务。FactorCaller是一个代表因子计算逻辑的接口,而Task则包含计算所需的上下文信息。每个因子的计算通过Future进行异步处理。
为了进一步提升响应式计算的能力,可以让因子实体继承自FutureTask类,这样可以实现更好的异步执行和回调机制。这种设计允许因子在计算完成后自动触发相关的后续操作,优化整个计算流程。


